IBM Watson にまだ馴染みのない方のために説明を加える。
特にここで話題としたいのは Watson Discovery の処理構造である。
まず最初に Watson を使うには IBM Cloud ( BlueMix ) にアカウントを
登録しなければならない。
Watson は IBM Cloud のサービスのひとつであるので、
まず Cloud にログインして、そこから Watson Discovery を使用することになる。
さらに Watson Discovery を試したいのであれば
自分独自の Watson の器(うつわ)を作成する必要がある。
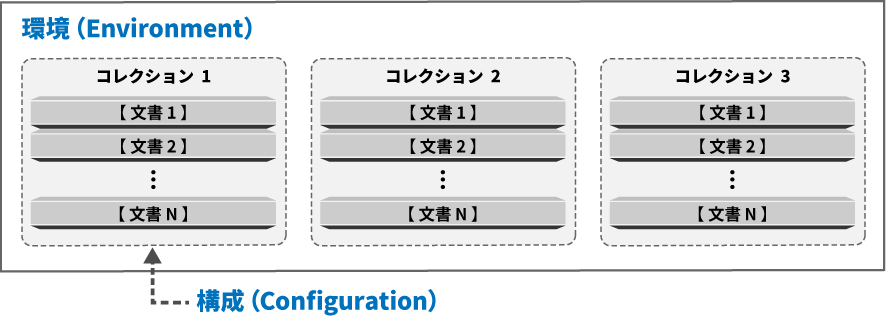
環境 ( Environment ) を作成します。環境はひとつのアカウントに対して
ひとつの環境を作成することができます。
2. コレクション ( Collection ) の作成
コレクション ( Collection ) とは文書管理の対象です。
例えば RPG 解説書、DDS 解説書、…などがコレクションとして
扱うことになります。
3. 構成 ( Configuration ) の定義
構成とはコレクションをどのような文書構成にするのかを
定義することを言います。
文書は HTML、PDF、Word などをコレクションに
アップロードするわけですが
どのような文書単位で区切るのかを構成によって定義します。
例えば PDF であればページ単位の文書として構成することができます。
4. 文書のアップロード
検索の対象としたい文書 ( HTML、PDF、Word など ) を
コレクション単位でアップロードします。
文書をアップロードするとコレクション内部では
細かな [ 文書1 ] [ 文書2 ] … [ 文書N ]に分割されて保存されます。
5. 検索
ここからがより重要ですが何か自然な文章を入力した質問すると
回答は [ 文書 ] 単位で戻ります。
つまり FAQ の回答の単位が [ 文書 ] となります。
6. 学習
得られたひとつひとつの [ 文書 ] に対して評価を Watson に戻します。
よくある「この回答は役に立ちましたか ?」という質問です。
この評価のフィード・バックによって Watson は学習します。