pipe を使うと2つのプロセス間通信を手軽に高速で結ぶことができることは既に紹介した。
UNIX で pipe が使われる場面は親となるサーバー・プログラムが子となるワーカー・プログラムを
spawn で投入して( i5/OS の SBMJOB と同じ ) 子のワーカー・プログラムの標準出力を
親サーバー・プログラムが標準入力として受け取る場合である。
この仕組みが使われている典型的な場面は Apache を代表とする HTTPサーバーである。
下図のように Apache のサーバー・デーモンはクライアントであるブラウザからの
要求を自分で読み取ってそれを子のワーカー・プログラムである子プロセスへ渡す。
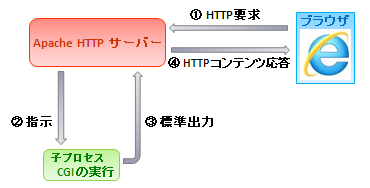
子プロセスである CGI は 応答としての ③HTMLを標準出力( STDOUT ) として出力し、
HTTPサーバーである Apache は、それを自分の標準入力( STDIN ) として入力してから
④HTTPコンテンツとして Apache がブラウザへ戻すのである。
つまり HTTPサーバー Apache と子プロセスのあいだは pipe によってプロセス間通信が行われている。

子プロセスであるCGI は結果の HTML を標準出力として出力すれば、親のApache の標準入力として
リダイレクトされるので非常に簡単に作成することができる。
ところが、この構造を良く見て欲しい。
クライアントのブラウザに対してつねに入出力を行っているのは Apache HTTPサーバーだけである。
数個の少ないクライアントの場合では問題ないがクライアント数が多くなると
Apache HTTPサーバーだけが入出力を頻繁に行うことになり、負荷がここに集中してしまい
結果として全体のパフォーマンスを著しく低下されることになってしまう。
それは別としても pipe は、このようなプロセス間の通信手段として利用される。
Apache が子プロセスを spawn 関数によって投入して、同時に pipe で標準関数をリダイレクト
させるというものである。
pipe の例はこのようなプロセス間通信をサンプルとするものが最も多くそれ以外の事例はほとんどない。
しかし System i で pipe を利用するときは、実は同一プロセス内における pipe の利用こそが
最も重要になってくることを後で紹介しよう。