68. System i 偺奜帤僥乕僽儖
System i 偺奜帤偼 暥帤嶌惉儐乕僥傿儕僥傿乕 (CGU) 偱僪僢僩扨埵偱巜掕偟偰嶌惉偡傞偙偲偼
椙偔抦傜傟偰偄傞丅
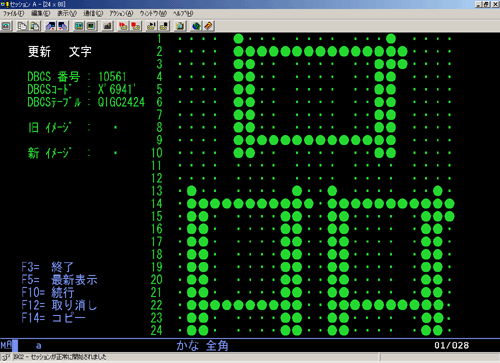
偦傟偱偼搊榐偟偨奜帤偼丄偳偙偵曐懚偝傟偰偄傞偺偩傠偆偐 ?
STRCGU 偱嶌惉偝傟傞偺偼 24x24僪僢僩偺奜帤偲 32x32僪僢僩偺奜帤偺2庬椶偑偁傝丄
24x24僪僢僩偺奜帤偼 QIGC2424 *IGCTBL 偲偄偆娍帤僥乕僽儖偵曐懚偝傟偰偍傝丄
32x32僪僢僩偺奜帤偼 QIGC3232 *IGCTBL 偲偄偆娍帤僥乕僽儖偵曐懚偝傟偰偄傞丅
*IGCTBL 丄偮傑傝娍帤僥乕僽儖偲偄偆僆僽僕僃僋僩偼丄捈愙丄偦偺拞恎傪嶲徠偡傞偨傔偺
僐儅儞僪傗API 傕梡堄偝傟偰偄側偄丅偮傑傝拞恎偼堦愗丄抦傞偙偲偑偱偒側偄丅
偙偺 System i 偵奜帤偑偁傞偐偳偆偐偩偗偼 CHKIGCTBL 僐儅儞僪偵傛偭偰
CHKOBJ 僐儅儞僪偺傛偆偵偟偰専嵏偡傞偙偲偑偱偒傞丅
偨偩偟 CHKIGCTBL 僐儅儞僪傕 CHKOBJ 僐儅儞僪埲忋偺婡擻偼側偄丅
桞堦丄CPYIGCTBL (DBCS太菽ッ疤拶 偺 核甙) 偲偄偆僐儅儞僪偵傛偭偰
娍帤僥乕僽儖傪暔棟僼傽僀儖偵僐僺乕偟偨傝丄暔棟僼傽僀儖偐傜娍帤僥乕僽儖偵
僐僺乕偟偨傝偡傞偙偲偑偱偒傞丅
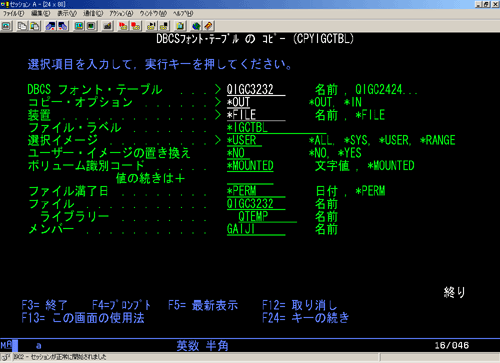
偝偰丄CPYIGCTBL 傪巊偆偵傕
- 庴偗擖傟懁偲側傞暔棟僼傽僀儖偼偳偺傛偆側傕偺傪梡堄偡傟偽傛偄偐 ?
- 曄姺偝傟偨暔棟僼傽僀儖偺僨乕僞偼丄偳偺傛偆側傕偺偐?
偑傢偐傜側偄偲 CPYIGCTBL 傪偳偺傛偆偵偟偰棙梡偡傟偽傛偄偐偼晄柧偱偁傞丅
幚偼 IBM 偼 CPYIGCTBL 僐儅儞僪偼僥乕僾摍偺攠懱偵BACKUP 偲偟偰僐僺乕偟偰偍偄偰
屻偱 BACKUP 偐傜栠偡傛偆側巊搑偟偐憐掕偟偰偄側偐偭偨傜偟偔偰 CPYIGCTBL 偺憡庤偲側傞
暔棟僼傽僀儖偺夝愢偑慡偔側偄丅
偦偙偱偙偙偱偼 *IGCTBL 偑曄姺偝傟偨暔棟僼傽僀儖偺儗僀傾僂僩偵偮偄偰徯夘偟傛偆丅
傑偢
| 僼僅儞僩丒僒僀僘 | 24x24 | 32x32 |
|---|---|---|
| 儗僐乕僪挿 | 74 僶僀僩 | 130 僶僀僩 |
偺暔棟僼傽僀儖傪師偺傛偆偵偟偰嶌惉偡傞丅
CRTPF FILE(QTEMP/QIGC2424) RCDLEN(74) MBR(GAIJI) IGCDTA(*YES) LVLCHK(*NO) AUT(*ALL)
傑偨偼
CRTPF FILE(QTEMP/QIGC3232) RCDLEN(130) MBR(GAIJI) IGCDTA(*YES) LVLCHK(*NO) AUT(*ALL)
亂拲亃 MEMOREX 幮偑PDF 偱 CPYIGCTBL 偺巊偄曽傪徻偟偔徯夘偟偰偄傞丅
iSeries400(AS/400)奜帤報嶞(PDF) 仸奜晹儕儞僋
師偵暔棟僼傽僀儖偺儗僀傾僂僩偼師偺傛偆偵峔惉偝傟偰偄傞丅
24x24僪僢僩偺奜帤偺応崌
-

32x32 僪僢僩偺奜帤偺応崌
-

偲偙傠偱 24x24 偺僀儊乕僕丒僨乕僞偱偁傟偽 24x24=576 僶僀僩偑昁梫偱偁傞偼偢偩偟丄
32x32 偺僀儊乕僕丒僨乕僞偱偁傟偽 32x32=1024 僶僀僩偑昁梫偱偁傞偼偢偱偁傞丅
側偤奺乆偼 70僶僀僩偲128僶僀僩偲抁偄偺偩傠偆偐 ?
偙傟偵偼棟桼偑偁傞丅
偙傟偼價僢僩儅僢僾撈帺偺埑弅曽朄偵傛偭偰栺1/8偵埑弅偝傟偰偄傞偺偱彫偝側僒僀僘偱嵪傫偱偄傞偺偱偁傞丅
偨偩偟偙偺僀儊乕僕丒僨乕僞偼捠忢偺價僢僩儅僢僾偲慡偔摨偠偲偄偆傢偗偱偼側偔丄
幚嵺偺價僢僩儅僢僾偵偡傞偵偼壓偐傜忋傊偲價僢僩儅僢僾偵婰弎偟偨傝曗悢傪寁嶼偟偨傝摍乆丄
寢峔柺搢側嶌嬈傪昁梫偲偡傞丅
- 嵟弶丄偙偺埑弅曽朄偺旤偟偝偵偼嬃偄偨偑偙傟偼 IBM 偺岺晇偱偼側偔價僢僩儅僢僾偺巇條偱偁傞偙偲偑屻偱傢偐偭偨丅
亂 IBM 娍帤僐乕僪懱宯 亃
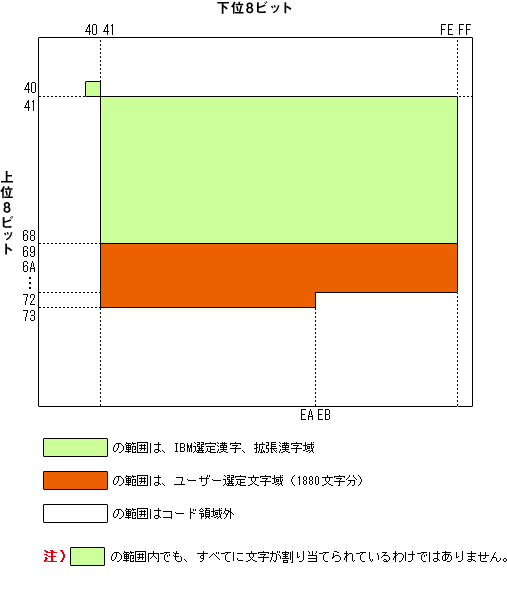
乵愢柧乶
偙偺恾偺傛偆偵奜帤(儐乕僓乕慖掕娍帤)堟偼 0x6941 偐傜巒傑偭偰 0x73EA 傑偱偺
暥帤偱偁傞丅
掕媊壜擻側奜帤偺憤悢偼 IBM 儅僯儏傾儖傪嶲徠偟偰傕條乆偱偁傝丄
擔杮岅娐嫬偱偁傟偽 嵟崅4370帤搊榐壜擻 偱偁傞偲彂偐傟偰偄偨傝偡傞偑丄
堦斒偵偼 1880暥帤 偲偝傟偰偄傞偑忋婰偺恾傛傝寁嶼偟偰傒傞偲
190 * 9 + 170 = 1880 暥帤悢暘偺奜帤偟偐掕媊偡傞偙偲偑偱偒側偄丅
堦曽偱 CGU 偺夋柺偵傛傟偽儐乕僓乕掕媊壜擻側奜帤偺娍帤斣崋偼 10561-16382 偲偁傞丅
16382- 10561 + 1 = 5800 暥帤偱偁傞丅
(恾偱偼傢偐傝偵偔偄偑忋埵價僢僩偼 68, 69, 6A, 6B, 6C, 6D, 6E, 6F, 70, 71, 72, 73 偲懕偄偰偄傞)
堦懱丄偳傟偑惓偟偄偺偱偁傞偺偐晄柧偩偑娍帤僐乕僪懱宯偑惓偟偄傛偆偵巚偊傞
擔杮偺応崌偼奜帤傪悢昐傕搊榐偡傞昁梫偑偁傞偙偲偼側偄偺偱崱偺偲偙傠栤戣偲偼
側傜側偄偑戜榩偺応崌偼斏懱帤偱偁傞偺偱庬椶偑懡偔丄摿偵恖柤偑奜帤偲偟偰
偐側傝偺悢偺搊榐偑昁梫偱偁傞偲偺偙偲偱偁傞丅
IBM 娍帤僐乕僪懱宯偼儅僯儏傾儖偱傕恾夝偝傟偰偄傞椺偼崱偱偼傎偲傫偳尒偮偐傜側偄偺偱
偁偊偰丄偙偙偱僐乕僪懱宯傪徯夘偟偨丅



